

Overview
Text-to-speech (TTS) technology reads aloud digital text. It can take words on computers, smartphones, tablets, and convert them into audio. Also, all kinds of text files can be read aloud, including Word, pages document, online web pages that can be read aloud. TTS can help kids who struggle with reading. Many tools and apps are available to convert text into speech.
Python comes with a lot of handy and easily accessible libraries and we’re going to look at how we can deliver text-to-speech with Python in this article.
Text to speech Conversion
Different API’s are available in Python in order to convert text to speech. One Such API’s is the Google Text to Speech commonly known as the gTTS API. It is very easy to use the library which converts the text entered, into an audio file which can be saved as an mp3 file.
It supports several languages and the speech can be delivered in any one of the two available audio speeds, fast or slow. More details can be found here
Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech computer or speech synthesizer and can be implemented in software or hardware products.
A text-to-speech (TTS) system converts normal language text into speech; other systems render symbolic linguistic representations like phonetic transcriptions into speech.
Synthesized speech can be created by concatenating pieces of recorded speech that are stored in a database. Systems differ in the size of the stored speech units; a system that stores phones or diphones provide the largest output range, but may lack clarity.
For specific usage domains, the storage of entire words or sentences allows for high-quality output. Alternatively, a synthesizer can incorporate a model of the vocal tract and other human voice characteristics to create a completely “synthetic” voice output.
The quality of a speech synthesizer is judged by its similarity to the human voice and by its ability to be understood clearly. An intelligible text-to-speech program allows people with visual impairments or reading disabilities to listen to written words on a home computer.
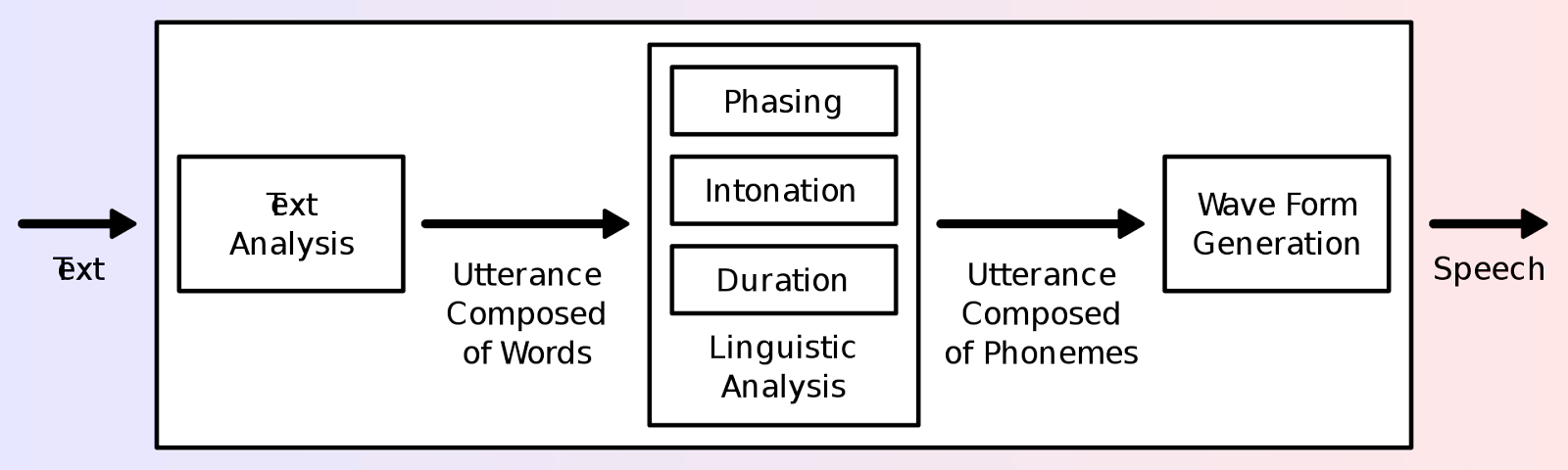
Many computer operating systems have included speech synthesizers since the early 1990s. A text-to-speech system (or “engine”) is composed of two parts: a front-end and a back-end. The front-end has two major tasks. First, it converts raw text containing symbols like numbers and abbreviations into the equivalent of written-out words. This process is often called text normalization, pre-processing, or tokenization.
The front-end then assigns phonetic transcriptions to each word and divides and marks the text into prosodic units, like phrases, clauses, and sentences. The process of assigning phonetic transcriptions to words is called text-to-phoneme or grapheme-to-phoneme conversion.
Phonetic transcriptions and prosody information together make up the symbolic linguistic representation that is output by the front-end. The back-end—often referred to as the synthesizer—then converts the symbolic linguistic representation into sound. In certain systems, this part includes the computation of the target prosody (pitch contour, phoneme durations), which is then imposed on the output speech.
Code
gTTS doesn’t have the same built-in Python functionality that gTTS does, so, first I have to install the package, to run my initial queries.
Now let’s jump to the coding approach to use the beauty of this package:
#Importing necessary files
from gtts import gTTS
import os
mytext = 'Enter your text which you want to convert '
# Language we want to use
language = 'en'Note: You can choose different languages provided by the Google. You can find list of languages here along with their code.
myobj = gTTS(text=mytext, lang=language, slow=False)
myobj.save("output.mp3")
# Play the converted file
os.system("start output.mp3")You can also convert list of text into desired speech by storing them in a .txt file using following lines of codes:
fh = open("test.txt", "r")
myText = fh.read().replace("\n", " ")
# Language we want to use
language = 'en'
output = gTTS(text=myText, lang=language, slow=False)
output.save("output.mp3")
fh.close()
# Play the converted file
os.system("start output.mp3") Advantages
- Only need a single model to perform text analysis, acoustic modeling and audio synthesis, i.e. synthesizing speech directly from characters
- Less feature engineering
- Easily allows for rich conditioning on various attributes, e.g. speaker or language
- Adaptation to new data is easier
- More robust than multi-stage models because no component’s error can compound
- Powerful model capacity to capture the hidden internal structures of data
- Capable to generate intelligible and natural speech
- No need to maintain a large database, i.e. small footprint
Disadvantages
Despite there are many advantages mentioned, end-to-end methods still have many challenges to be solved:
- Auto-regressive-based models suffer from slow inference problem
- Output speech are not robust when data are not sufficient
- Lack of controllability compared with traditional concatenative and statistical parametric approaches
- Tend to learn the flat prosody by averaging over training data
- Tend to output smoothed acoustic features because the l1 or l2 loss is used
Applications
Speech synthesis has long been a vital assistive technology tool and its application in this area is significant and widespread. It allows environmental barriers to be removed for people with a wide range of disabilities.
The longest application has been in the use of screen readers for people with visual impairment, but text-to-speech systems are now commonly used by people with dyslexia and other reading difficulties as well as by pre-literate children.
They are also frequently employed to aid those with severe speech impairment usually through a dedicated voice output communication aid.
Speech synthesis techniques are also used in entertainment productions such as games and animations. In 2007, Animo Limited announced the development of a software application package based on its speech synthesis software FineSpeech, explicitly geared towards customers in the entertainment industries, able to generate narration and lines of dialogue according to user specifications.
The application reached maturity in 2008 when NEC Biglobe announced a web service that allows users to create phrases from the voices of Code Geass: Lelouch of the Rebellion R2 characters.
In recent years, text-to-speech for disability and handicapped communication aids have become widely deployed in Mass Transit. Text-to-speech is also finding new applications outside the disability market. For example, speech synthesis, combined with speech recognition, allows for interaction with mobile devices via natural language processing interfaces.
Text-to-speech is also used in second language acquisition. Voki, for instance, is an educational tool created by Oddcast that allows users to create their own talking avatar, using different accents. They can be emailed, embedded on websites, or shared on social media.
In addition, speech synthesis is a valuable computational aid for the analysis and assessment of speech disorders. A voice quality synthesizer, developed by Jorge C. Lucero et al. at the University of Brasilia, simulates the physics of phonation and includes models of vocal frequency jitter and tremor, airflow noise, and laryngeal asymmetries. The synthesizer has been used to mimic the timbre of dysphonic speakers with controlled levels of roughness, breathiness, and strain.